Javascript-ES6-函数式编程阅读随写
函数式编程简介
函数要小,要更小.
函数式编程,远离外部环境的依赖,隔绝突变与状态.
数学的函数定义中,函数必须接收一个参数,返回一个值.函数根据接收的参数运行.给定的参数下,返回值是不变的.
JavaScript函数式编程基于数学函数及其思想进行发展.运用函数式的范式进行开发能创造可缓存和可测试的代码库.
简单分辨函数与方法 - JS,不必深究 window 和 global 对象.
- 函数: 一段通过名称可调用的代码
- 方法: 通过名称且关联对象的名称被调用的代码
函数的引用透明性指的是,函数对相同的输入返回相同的值.不依赖全局数据的函数,能够自由地在多线程状态下运行,全程无锁.并且函数是可缓存的,合理运用这一点,可以节省大量重复计算的资源消耗和时间消耗.
引用透明性是一种哲学
命令式?声明式?
const arr = [1, 2, 3];
for (i = 0; i < arr.length; i++) console.log(i);
上述代码示例,我们告诉编译器如何去做,这就是命令式.
const arr = [1, 2, 3];
arr.forEach((i) => console.log(i));
forEach是一个高阶函数,意在告知编译器做什么,如何做的部分则在高阶函数内的普通函数中实现.这便是声明式.
纯函数:对给定的输入,返回相同的输出的函数.纯函数不依赖于外部环境.也不会改变外部环境.易于对函数进行测试.
纯函数是易于阅读的.为纯函数设置具有意义的函数名是一种最佳实践.
纯函数应该被设计为只做一件事,并且把它做到完美,这也会是 Unix 的哲学.
纯函数支持管道和组合.
cat package.json | grep axios
bash命令的管道和组合威力巨大,组合是函数式编程的核心.我们称之为function composition.
JavaScript 函数式基础
略,简述基础JavaScript.
高阶函数 HOF
JavaScript 数据类型:
- Number
- String
- Boolean
- Null
- Object
- undefined
- Symbol
- BigInt
除了object外,都是原始数据类型.
在计算机科学中,抽象化(英语:Abstraction)是将资料与程序,以它的语义来呈现出它的外观,但是隐藏起它的实现细节。抽象化是用来减少程序的复杂度,使得程序员可以专注在处理少数重要的部分。一个电脑系统可以分割成几个抽象层(Abstraction layer),使得程序员可以将它们分开处理。
抽象化,让我们专注于可控层面的工作,将复杂的内容简单化,让开发者专注于预订的目标,不必事事关心.
我们通过高阶函数实现抽象.
const forEach = (arr, Fn) => {
for (let i = 0; i < arr.length; i++) Fn(arr[i]);
};
这是一个简单的高阶函数,抽象了遍历数组的问题,如果你使用这个函数,你并不需要关注内部代码是如何实现的.上述例子是一个简单逻辑,同理也可以是更为复杂的逻辑,这样一来就将复杂问题抽象出来了.
让我们开始学习构建复杂的高阶函数.
创建一个every函数如下:
const every = (arr, fn) => {
let result = true;
for (const i = 0; i < arr.length; i++) {
result = result && fn(arr[i]);
}
return result;
};
// for..of.. 版本
// for...of..是 es6 的函数,可以方便遍历数组
const every = (arr, fn) => {
let result = true;
for (const value of arr) {
result = result && fn(arr[value]);
}
return result;
};
如此一来,我们抽象了对数组遍历的操作.
接着,编写一个some函数,其接受一个数组和一个函数,如果数组中一个元素通过接收的函数返回true,则some函数返回true:
const every = (arr, fn) => {
let result = true;
for (const value of arr) {
result = result || fn(arr[value]);
}
return result;
};
some 函数和 every 函数都不算高效,这里只是作为对高阶函数的展示.
JavaScript的array原型内置sort函数,可以给数组排序.这是一个典型的高阶函数.它接收一个可选的函数来决定排序顺序逻辑.极大的提高了排序的灵活性.我们知道,默认的sort排序是将数组元素转换为string并且按Unicode编码点进行排序,因此数字 2 在默认排序算法中小于 12.让我们看看此可选的compare函数的骨架:
function compare(a, b) {
if (条件) {
// a 小于 b
return -1;
}
if (条件) {
// a 大于 b
return 1;
}
// a 等于 b
return 0;
}
举个例子,现在我们有一个用户数组,每个元素是一个用户的信息.
const people = [
{
name: "Aaron",
age: 10,
},
{
name: "Rose",
age: 11,
},
];
而需求则是,通过姓名排序或者通过年龄排序.根据前置知识,可以写出如下代码:
// 简化逻辑,忽略相等的情况
people.sort((a, b) => (a.name > b.name ? 1 : -1));
people.sort((a, b) => (a.age > b.age ? 1 : -1));
上述代码,我们将雷同的部分写了两遍.现在我们来设计一个函数,接收一个参数,返回一个函数.是的,将要设计的这个函数是一个高阶函数.
const sortBy = (property) => {
return (a, b) => {
return a[property] > b[property] ? 1 : -1;
};
};
// 简化版
const sortBy = (property) => (a, b) => a[property] > b[property] ? 1 : -1;
现在,我们可以重写按name或者age的排序代码了.
people.sort(sortBy("name"));
people.sort(sortBy("age"));
这就是高阶函数的魅力.运用高阶函数,提高代码质量,降低代码数量.
闭包与高阶函数
简而言之,闭包就是一个内部函数.在一个函数内部的函数,可以称为闭包函数.
从技术上来讲,上述闭包函数的闭包场景存在三个可访问的作用域:
- 自身声明内变量
- 外部函数变量
- 全局变量
闭包可以记住上下文环境.话说回来,由于我们要在函数式编程中处理很多函数,因此需要一种调试方法.
举个例子,一个字符串数组,想要解析成整数数组,如下代码会有问题:
["1", "2"].map(parseInt);
map函数用三个参数调用了parseInt,分别是:
- element
- index
- arr
而parseInt函数全盘接纳,来看看此函数的定义:
parseInt(string, radix);
radix是可选的基数,如果提供 10,则转换为十进制的整数.
如果 radix 是 undefined、0或未指定的,JavaScript 会假定以下情况:
- 如果输入的
string以 "0x"或 "0x"(一个 0,后面是小写或大写的 X)开头,那么 radix 被假定为 16,字符串的其余部分被当做十六进制数去解析。 - 如果输入的
string以 "0"(0)开头,radix被假定为8(八进制)或10(十进制)。具体选择哪一个 radix 取决于实现。ECMAScript 5 澄清了应该使用 10 (十进制),但不是所有的浏览器都支持。因此,在使用parseInt时,一定要指定一个 radix。 - 如果输入的
string以任何其他值开头,radix是10(十进制)。
如果第一个字符不能转换为数字,parseInt会返回 NaN。
此时,['1', '2'].map(parseInt)的结果是: [1, NaN].
如何用函数式的思维,创建一个高阶函数,对parseInt进行抽象.
const unary = (fn) =>
fn.length === 1 ? fn : (arg) => fn(arg)[("1", "2", "3")].map(unary(parseInt));
现在,即使map以三个参数调用unary函数执行后返回的函数,都只会让element参数生效.
我们得到了预期中的结果:[1,2,3] :seedling:
现在,让我们为自己的工具库添加一个工具函数,这个函数接收一个函数作为参数,让这个接收的函数只能被执行一次.
const once = (fn) => {
let done = false;
return () => (done ? undefined : ((done = true), fn.apply(this, arguments)));
};
现在用一个变量done保存函数的执行状态.
const demoFn = (a, b) => {
console.log(a, b, "just called once.");
};
const newDemoFn = once(demoFn);
newDemoFn(1, 2); // output: 1 2 just called once.
newDemoFn(3, 4); // no output
继续,创建下一个函数memoized,使函数记住其计算结果:
const memoized = (fn) => {
const lookupTable = {};
return (arg) => lookupTable[arg] || (lookupTable[arg] = fn(arg));
};
一个速查table保存了函数解构,如果不存在则执行此函数,保存到速查表中并且返回此结果.
memoized 函数是经典的函数式编程,是闭包与纯函数的实战
数组的函数式编程
我们将创建一组函数用于解决常见的数组问题,关键在于函数式的方法,而非命令式的方法.
把函数应用于一个值,并且创建新的值的过程被称为"投影"
Array.map就是典型的投影函数.我们来试着创建一个map函数.
const map = (arr, fn) => {
const result = [];
for (const v of arr) {
result.push(fn(v));
}
return result;
};
一个filter函数,对数组内容进行过滤.
const filter = (arr, fn) => {
const result = [];
for (const v of arr) {
if (fn(v)) result.push(v);
}
return result;
};
一个reduce函数,对数组的所有值进行归约操作.
var reduce = (arr, fn, defaultAccumlator) => {
let accumlator;
if (defaultAccumlator !== undefined) {
accumlator = defaultAccumlator;
for (const v of arr) {
accumlator = fn(accumlator, v);
}
} else {
accumlator = arr[0];
for (let i = 1; i < arr.length; i++) {
accumlator = fn(accumlator, arr[i]);
}
}
return [accumlator];
};
继续,上zip函数,用于合并两个单独的数组,返回一个处理过的新数组.这个函数可以对给定的两个数组的限定对象进行结对处理,如何处理取决于具体的函数逻辑.结对的结果就是返回一个新的数组.
const zip = (arr1, arr2, fn) => {
let index,
result = [];
for (index = 0; index < Math.min(arr1.length, arr2.length); index++) {
result.push(fn(arr1[index], arr2[index]));
}
return result;
};
currying 和偏应用
一些术语:
- unary function: 一元函数,只接收一个参数的函数.
- binary function: 二元函数
- 变参函数:接受可变数量参数的函数
- currying: 柯里化,这是一个过程,将一个多参函数转变为一个嵌套的一元函数.
上代码:
const curry = (binaryFn) => {
return (firstArg) => {
return (secondArg) => {
return binaryFn(firstArg, secondArg);
};
};
};
// 简化
const curry = (binaryFn) => (firstArg) => (secondArg) =>
binaryFn(firstArg, secondArg);
完美利用了闭包的特性,也许对于一些深谙此道的 coder 而言,这不算什么.但是对于此刻的我来说,从未如此清晰体会到闭包和 currying.如此之美.
开发者编写代码的时候会在应用中编写日志,下面我们编写一个日志函数.
const loggerHelper = (mode, msg, errorMsg, lineNo) => {
if (mode === "DEBUG") {
console.debug(msg, errorMsg + "at line:" + lineNo);
} else if (mode === "WARN") {
console.warn(msg, errorMsg + "at line:" + lineNo);
} else if (mode === "ERROR") {
console.error(msg, errorMsg + "at line:" + lineNo);
} else {
throw "WRONG MODE";
}
};
上述代码不是良好的设计,多次重用了部分代码,让整体不够简洁.之前创建的curry函数也无法处理这个日志函数.我们需要更进一步.我们需要把多参数函数转化为unary function.
const curry = (fn) => {
if(typeof fn !== 'function') throw Error('No function provided')
// args 是可变参数
return function curryFn(...args) {
// 如果可变参数少于被柯里化的函数的参数数量
if(args.length < fn.length) {
return function() {
// 执行此函数,返回一个处理一次参数的函数
return curryFn.apply(null, args.concat(
Array.slice.call(arguments)
))
}
}
return fn.apply(null, args)
}
arguments对象是所有(非箭头)函数中都可用的局部变量。你可以使用arguments对象在函数中引用函数的参数。此对象包含传递给函数的每个参数,第一个参数在索引 0 处。
回到日志函数:
const errorDebugLog = curry(loggerHelper)("ERROR")("ERROR:");
const warnDebugLog = curry(loggerHelper)("WARN")("WARN:");
errorDebugLog("balabala..", 21); // output: 'ERROR: balabala at line 21'
这就是闭包的魅力,在首次传入loggerHelper的时候,闭包生成了可访问变量作用域,记住了函数信息.
现在,让我们来解决两个问题:
- 在数组内容中检查是否存在数字
- 求数组的平方
首先,创建一个检查函数:findNumberInArr
const match = curry((expr, str) => str.match(expr));
const hasNumber = curry(match(/[0-9]+/));
const filter = curry((fn, arr) => arr.filter(fn));
// create fn
const findNumberInArr = filter(hasNumber);
// test
findNumberInArr(["demo", "demo1"]); // output: ['demo1']
现在求数组的平方,我们通过curry函数进行处理,这次不要直接通过map函数传入一个平方函数解决这个问题.换一个视角.
const map = curry((fn, arr) => arr.map(f));
const squareAll = map((x) => x * x);
// 现在,squareAll 是一个unary 函数
squareAll([1, 2, 3]); // output: [1, 4, 9]
我们可以很多地方直接使用squareAll函数了.如果需要在多个地方求数组的平方,这个函数可以简化降低代码量,当然,我们还可以配合memoized函数进行缓存处理!
是时候谈谈偏应用了,接下来我们将创建一个partial函数以解决我们的问题.
比如我们有这样一个场景,我们需要在 10 秒后执行一个函数,这个需求在多个地方用得上,也许我们会直接如此编程:
setTimeout(() => {
// some code
}, 10000);
一旦需要在另一个地方使用这个逻辑,就需要重写一遍这些代码.而且无法使用curry函数进行处理,因为时间参数是最后一个参数.解决这个问题的方案之一就是创建一个封装函数:
const setTimeoutWrapper = (time, fn) => {
setTimeout(fn, time);
};
然后使用curry函数进行优化.然而,我们可以进一步减少创建此类函数的开销.
这就是偏应用的应用场景.
var partial = (fn, ...partialArgs) => {
let args = partialArgs
return (...fullArguments) {
let arg = 0
for(let i=0;i<args.length && arg < fullArguments.length;i++) {
if(args[i] === undefined) {
args[i] = fullArguments[arg++]
}
}
return fn.apply(null, args)
}
}
const delayTenMs = partial(setTimeout, undefined, 10)
const demoFn = () => {
// sdasdsadad
}
delayTenMs(demoFn)
再次使用了闭包,记住了setTimeout需要的参数列表长度,暂未提供的参数用 undefined 代替.后续返回一个函数,提供参数的同时,补全之前用 undefined 代替的部分参数,最终执行函数.
例如,我们需要美化一个json对象的输出.先看看 json stringify 函数的定义.
JSON.stringify(value[, replacer [, space]])
参数
value将要序列化成 一个 JSON 字符串的值。
replacer可选如果该参数是一个函数,则在序列化过程中,被序列化的值的每个属性都会经过该函数的转换和处理;如果该参数是一个数组,则只有包含在这个数组中的属性名才会被序列化到最终的 JSON 字符串中;如果该参数为 null 或者未提供,则对象所有的属性都会被序列化。
space可选指定缩进用的空白字符串,用于美化输出(pretty-print);如果参数是个数字,它代表有多少的空格;上限为 10。该值若小于 1,则意味着没有空格;如果该参数为字符串(当字符串长度超过 10 个字母,取其前 10 个字母),该字符串将被作为空格;如果该参数没有提供(或者为 null),将没有空格。
const obj = { foo: "bar", bar: "foo" };
// 第二参数
JSON.stringify(obj, null, 2);
// 想办法移除样板代码 null 和 2
const prettyJson = partial(JSON.stringify, undefined, null, 2);
prettyJson(obj);
啊!partial函数有 bug.partialArgs传递的是数组,数组传递的是引用.如果不创建一个新的数组,并且在最后重置数组的话,执行一次partial化后的函数delayTenMs,内部 args 就固定了,闭包变量保存了首次执行的时候提供的参数去替换undefined,这里的undefined就像占位符.
书上并没有给出一个示例代码来解决问题,只是提出存在 bug 的观点,我写下了如下代码,使用扩展运算符重置占位符效果的undefined变量.
const partial = (fn, ...partialArgs) => {
let args = [...partialArgs];
return (...fullArgs) => {
let argIndex = 0;
for (
let index = 0;
index < args.length && argIndex < fullArgs.length;
index++
) {
if (args[index] === undefined) {
args[index] = fullArgs[argIndex++];
}
}
const result = fn.apply(null, args);
args = [...partialArgs];
return result;
};
};
晚安.
2020 年 12 月 21 日 01:41:11
管道和组合
函数式组合在函数式编程中被称为组合 composition.
每个程序只为做好一件事,重构要比在旧的复杂程序中添加新属性更好. From Ken·Thompson
每一个程序的输出应该是另一个未知程序的输入.
我们将要创建compose函数,例如:
const compose = (a, b) => (c) => a(b(c));
依然是熟悉的高阶函数,接收函数作为参数,返回函数.返回的函数的参数是关键.
compose函数能解决我们常见的一些问题.你是否写过类似如下代码:
const data = someFn("this");
const result = otherFn(data);
一个函数的输出,作为另一个函数的输入.compose函数为此而生.
const getResult = compose(otherFn, someFn);
getResult是一个函数,接收的参数跟someFn函数一致.我们创建了一个函数getResult.这是一种优雅而简单的实现方式.
上述someFn只接收一个参数,如果需要接收多个参数的话,我们可以使用curry和partial两个函数进行优化.
组合的思想就是把小函数组合成大函数,简单的函数易于阅读,测试和维护.
创建小的函数单元,可以通过 compose 组合重建应对各种需求.
但是,上述compose函数无法处理更多函数作为参数.仅仅支持两个函数作为参数是不够的,让我们来优化一下.
const compose =
(...fns) =>
(value) =>
reduce(fns.reverse(), (acc, fn) => fn(acc), value);
竟然如此简单桥面,接收一个入口参数value,首先设置为初始的acc值,依次执行并且返回作为下一个函数的入口.
组合是从右到左执行的,而管道则从左到右.接下来创建pipe管道函数.
const pipe =
(...fns) =>
(value) =>
reduce(fns, (acc, fn) => fn(acc), value);
只是执行方向不同而已,因此参数列表不必反向.
在公共代码库中建议使用单一的数据流,我更喜欢管道,因为这让我想起 shell 知识.同时使用管道和组合容易在团队中引起混淆.
接下来,本书描述了组合的优势.
组合支持结合律.书上并没有详细的介绍和案例分析.只是单纯举例:
compose(f, compose(g, h)) == compose(compose(f, g), h);
通过组合小函数的方式,让函数的组合更加灵活.
下面,我们来创建一个identity函数,用于分析调试.接收一个参数,打印并且返回.
const identity = (it) => {
console.log(it);
return it;
};
由于组合和管道数据是流动的关系,可以在其间插入identity函数,输出数据用于调试.这确实非常简单有效.
函子
本章最重要的内容就是编程错误处理.我们需要了解一个新的概念:functor:函子,它将以纯函数的形式帮我们处理错误.
函子是一个普通对象,它实现了
map函数,在遍历每一个对象的时候生成一个新的对象.
函子是容器,其持有值.
const Container = function (val) {
this.value = val;
};
不使用箭头函数,箭头函数没有
[[construct]]和prototype属性,无法用new实例化.
现在,container可以持有传给它的任何值.
let a = new Container(3)
=> Container(value: 3)
let bObj = new Container({a: 1})
=> Container({a:1})
继续,创建一个of静态方法.
Container.of = function (value) {
return new Container(value);
};
于是,我们可以使用static函数创建对象了.
const testObj = Container.of(3)
=> Container(value:3)
接下来,我们需要创建map函数,之后这便是一个函子.
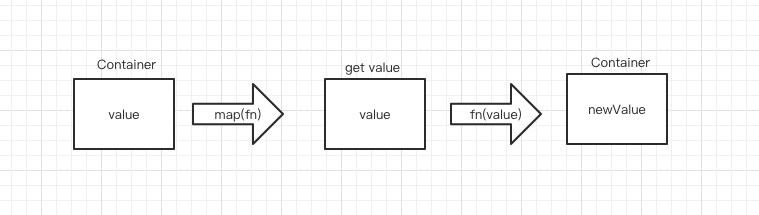
看代码:
Container.prototype.map = function (fn) {
return Container.of(fn(this.value));
};
经过map函数处理,会返回一个新的 container 对象.于是,我们可以进行如下编码:
let double = x => x + x
Container.of(3).map(double)
=> Container(6)
Container.of(3).map(double).map(double)
=> Container(12)
得到了我个人一直以来不够了解的链式调用的实现思路.
函子是一个实现了 map 契约的对象
所以,函子能用在什么地方?
const MayBe = function (val) {
this.value = val;
};
MayBe.of = function (v) {
return new MayBe(v);
};
MayBe.prototype.isNothing = function () {
return this.value === null || this.value === undefined;
};
MayBe.prototype.map = function (fn) {
return this.isNothing() ? MayBe.of(null) : MayBe.of(this.value);
};
:construction_worker:
上用例
MayBe.of('string').map(x => x.toUpperCase())
=> MayBe {value: 'STRING'}
即使不是typescript,无法避免of方法传入null或者undefined,内部的map方法也会做一次检查,逻辑抽象出来避免了错误.代码没有在null或者undefined下崩溃.这是一种声明式的方式去编程,这也是一个安全的容器.
MayBe.of("pg")
.map((x) => x.toUpperCase())
.map((x) => `Mr. ${x}`);
链式调用,优美简洁.
另一个函子Either,上述MayBe函子在传入null或者undefined后,最后的结果是null.可是我们很难分析出问题出在哪里.我们需要一个更强大的函子,解决分支拓展的问题.
const Nothing = function (val) {
this.value = val;
};
Nothing.of = function (v) {
return new Nothing(v);
};
Nothing.prototype.map = function (f) {
return this;
};
const Some = function (val) {
this.value = val;
};
Some.of = function (v) {
return new Some(v);
};
Some.prototype.map = function (f) {
return Some.of(f(this.value));
};
Nothing的 map 函数,返回自身,而不是运行函数f.
2020 年 12 月 25 日 12:57:10 :100:
能在Some上运行函数,而Nothing不行.来吧,实现Either.
const Either = {
Some,
Nothing,
};
如果我们有一个web请求,返回数据可能是正常数据,或者一条错误信息.
const getData = (type) => {
let resp;
try {
resp = Some.of(data);
} catch {
resp = Nothing.of(error);
}
};
后续返回的 response 对象依然是函子,可以使用链式调用的 map 函数.但是,错误信息能保存下去,Nothing从头到尾都不会变,直接返回this使得后续的 map 函数失效.
现在,你根据上下文,可以很容易看出异常出在哪里.是的,是catch到了错误.
上述函子都是pointed函子,ES6 的 Array.of 也是pointed函子.
深入理解 Monad 函子
reddit开放了一些api接口,例如:https://www.reddit.com/search.json?q=something
粘贴一个随机的返回数据,不必详细深究:
{
"kind": "Listing",
"data": {
"after": "t3_k1qcrx",
"dist": 25,
"facets": {}.
"modhash": "",
"children": [...],
"before": null
}
}
children部分非常庞大,不再展开.每一个children都是一个对象,内含一个Permalink键,值是一个相对url,访问这个url则能获取到评论数组.
我们如何按搜索的结果,获取文章的评论,最后返回一个数组,每个元素是一个对象,对象内是title和comments.
const request = require("sync-request");
const searchReddit = (search) => {
let response;
try {
response = JSON.parse(
request(
"GET",
"https://www.reddit.com/saerch.json?q=" + encodeURI(search)
).getBody("utf8")
);
} catch (err) {
response = { msg: "something wrong", errorCode: err["statusCode"] };
}
return response;
};
const getComments = (link) => {
let resp;
try {
resp = JSON.parse(
request("GET", "https://www.reddit.com/" + link).getBody("utf8")
);
} catch (err) {
resp = {
msg: "get comment failed",
errorCode: err["statusCode"],
};
}
return resp;
};
// 合并两个函数
const mergeViaMayBe = (searchText) => {
let redditMayBe = MayBe.of(searchReddit(searchText));
let ans = redditMayBe
.map((arr) => arr["data"])
.map((arr) => arr["children"])
.map((arr) =>
map(arr, (x) => {
return {
title: x["data"].title,
permalink: x["data"].permalink,
};
})
)
.map((obj) =>
map(obj, (x) => {
return {
title: x.title,
comments: MayBe.of(
getComments(x.permalink.replace("?ref=search_posts", ".json"))
),
};
})
);
};
运用函子,可以使用链式方法解决问题,非常优雅.
但是,这依然不够,观察上述结果中comments依然是MayBe对象,想要真正取值还是需要继续map调用.
下面,介绍Monad函子以解决过多的map嵌套问题.让MayBe武装到牙齿.
MayBe.prototype.join = function () {
return this.isNothing() ? MayBe.of(null) : this.value
}
let joinExample = MayBe.of(MayBe.of(1))
=> MayBe{value: MayBe{value: 1}}
joinExample.join()
// 返回值展开一个层级
=> MayBe {value: 1}
如果我们想要对内部的值进行操作,也许可以先展开层级,再执行map函数,以减少map的调用.那么既然当我们需要展开一层的时候都需要在后面跟一个join方法,我们可以再封装一个chain函数来做这件事.
MayBe.prototype.chain = function (f) {
return this.map(f).join();
};
Monad就是包含chain方法的特殊函子.或者说,一个函子拥有chain方法,就可以称为Monad
2020 年 12 月 26 日 01:34:57
使用 Generator
如果你是promise的粉丝,建议学习Generator及其解决异步代码问题的方式.
让我们先来谈谈同步和异步:
同步:函数执行的时候阻塞调用者,直到函数执行结束返回结果.
异步:函数执行不会阻塞,但是函数执行结束就会返回结果.
让我们来创建Generator,注意观察这个特殊语法.
function* gen() {
return "first generator";
}
我们在函数前面用一个星号 * 来表示这是一个Generator函数.
let genResult = gen();
此刻,genResult并不是first generator,而是:
gen {[[GeneratorStatus]]: "suspended", [[GeneratorRecevier]]: Window}
这是一个Generator原始类型的实例.这个实例拥有next方法.执行此方法,上面的代码返回一个对象:
{value: 'first generator', done: true}
Generator实例如同序列,一旦使用next消费,则不能再次得到上次消费的值.也就是说,如果你继续执行next()方法,结果的vaue将是undefined.
function* gen() {
yield 1;
yield 2;
yield 3;
}
有趣的是,实例执行next将会返回yield后的结果,并且下次执行next会从当前yield后继续执行.当所有yield结果都消费之后,done属性变成true.
let genResult = gen();
for (let v of genResult()) {
console.log(v);
}
// 1
// 2
// 3
for..of..利用了next和done属性完成遍历.
Generator不止如此,还可以想其实例通过next函数传递数据.
function * sayFullName(){
let firstName = yield
let secondName = yield
console.log(`${firstName} - ${secondName}`)
}
// call it
let fullName = sayFullName()
fullName.next()
fullName.next('Fname')
fullName.next('Sname')
=> console log : Fname - Sname
首次运行next,函数暂停于: let firstName = yield
再次运行带参数的next,则let firstName = yield转为let firstName = "Fname"
Generator与异步应用可以很和谐.
假如有两个本质上是异步的函数如下:
let getDataOne = (cb) => {
setTimeout(() => {
cb("dummy data one");
}, 1000);
};
let getDataTwo = (cb) => {
setTimeout(() => {
cb("dummy data two");
}, 1000);
};
一旦时间过去,就执行传入的回调函数cb.如果要用generator来解决回调函数可能导致的函数回调地狱的问题?
让我们来改造getDataOne:
let geneator;
let getDataOne = () => {
setTimeout(() => {
// 调用 Generator
// 使用 next 加参数传送数据
generator.next("fake data one");
}, 1000);
};
然而,我并不是很理解这段代码,generator是undefined,为何调用next.
2020 年 12 月 26 日 22:56:50
2020 年即将结束,在异步编程的问题上让我们拥抱async和await吧.
终于看完了这本书,这本书非常适合我现在的水平,让我能够学习得很愉快.再次感谢,即使昨天是圣诞节我依然一个人过.
再会啦.
